イギリスのプリペイド SIM カードは、
ほとんど (全て?) のキャリアの SIMカードが無料でもらえる (送料も無料)。
日本を出発する前日に、
以下の 10キャリアの free SIM を Web で申し込んでみた。
ただし、
SIM の送付先は英国内の住所限定なので、
宿泊予定のホテルの住所を指定しておく。
T-Mobile
は英国の電話番号が必須入力項目なので、
sipgate で得た電話番号を指定した。
free SIM といっても、
もちろん電話代がタダになるわけではなく、
通信・通話を行なうには SIM に度数をチャージ (英国では Top up と呼ぶ)
する必要がある。
Top up は Web 上でできる (クレジットカード払い) ので、
ショップ等に行く必要も、
英語で会話する必要もない (英語が苦手な私にとって重要なポイント)。
もちろん、
英国のいたるところ (コンビニ、スーパー等、
「PayPoint」
あるいは
「top-up」
の看板が出ている店) で Top up のための
Voucher (PIN が印字されたレシート) を購入することもできる。
ヒースロー国際空港に着くと、
プリペイドSIM の自動販売機が到着ロビーの目立つところにおいてある。
しかし SIM だけ (つまり度数無し) で£10 もする。
free SIM を申し込んでしまった手前、
£10 も払うわけにはいかない。
ロンドンの街中では同じものが£1〜£3 程度で購入できるようだ。
ホテルに着いてチェックインし、
真っ先に郵便物の有無をたずねたが、
さすがに昨日の今日では届いていなかった。
出発 2日前に申し込んでおけばよかったかも?
giffgaff は、
申し込んでから発送まで 2日ほどかかる
(発送した旨を知らせるメールが申込日の 2日後に届いた)
ので、
出発 3日前に申し込むのがよさげ。
早く申し込みすぎてチェックイン前に届いてしまうと、
ホテルによっては受け取りを拒否されるかも?
部屋の状態 (お湯が出るとか、破損個所が無いかとか) を確認し、
無線LAN (があることは事前に確認済)
を使おうとしたら有料だった。
しかも高い。
一日分の使用料金でケータイの通信・通話料金の一ヶ月分くらいする。
仕方ないので、
既に 19:00 をまわっていた (日本時間だと 3:00 過ぎなので眠い) が、
SIM を買いに最寄り駅 (Earl's Court) まで行ってみる。
閉ってる店も多かったが、
幸いコンビニは開いていて
(ロンドンは 10年ぶりで、
前回訪問時は 19:00 過ぎに開いてる店は皆無だったような記憶が...)
Vodafone SIM (と£10 Top up Voucher) を買うことができた
(本当は 3UK SIM を買いたかったのだが、無いと言われた)。
Vodafone
通話料は 25ペンス/分、
インターネットへアクセスする際のデータ通信
(以下、Web と略記。もちろん Web 以外の通信も可能)
の料金は 25MB あたり£1 (一日最大£5)。
ただし、
Text & Web パッケージを選択 (opt in) した場合は、
£10 を Top up すると、
300通までの国内 SMS (300 text と略記) と、
500MB までの Web (500MB web と略記) が無料になる (30日間有効)。
30日の間に Web が 500MB の枠を超えそうな場合
(スマホを使ってると超えることが多い) は、
£5 の Web Pack を購入することにより Web 枠を 250MB 追加できる。
Web 枠を使い切ると、
25MB あたり£1 の Web 料金が適用されてしまうので、
使い切る前に Web Pack を購入しておくべき。
Web Pack は 5個まで先行して購入しておくことが可能。
Web Pack は、
My account
を登録しておくことにより、
クレジットカード払いで購入できる。
Top up のように、
My account を登録せずに購入する方法があるかどうかは未確認。
なお、
街中で売ってる SIM は (Vodafone に限らず)
International パッケージ (つまり国際電話が安くなるパッケージ)
を選択して使うことを想定している。
プリペイドSIM 購入者の大半が、
(おそらく母国へ) 国際電話をかけるために SIM を買うからだろう。
SIM 同梱の説明書には、
「4351」
をダイヤルして activate する方法のみ記載されているが、
この activate 方法では£10 を Top up しても Web 料金の特典はなく、
その代わり 60分までの国際通話が無料になる。
私は国内通話とインターネットへのアクセスさえできればいいので、
Text & Web パッケージを選択したかったのだが、
インターネットにアクセスできない状況下では
activate の番号を調べる手段が無かった。
泣く泣く 4351 をダイヤルした後、
SIM と同時に購入した£10 Top up Voucher の PIN を入力した。
さらに悪いことに、
Web Pack の購入方法に気付いたときには既に残高が£5 を下回っていて
(Web Pack 無しだと 1日最大£5 の Web 料金がかかるので £10 が
2〜3日で無くなる)
Web Pack を購入することができなかった。
SIM の activate 方法は、
インターネットにアクセスできない状況下で必要となることを想定し、
事前にメモしておくべきだろう。
以下にまとめておく:
£5 Weekend パッケージは、
月曜〜金曜に£5 を Top up すると、
土曜と日曜の通話が 100分まで無料になり、
土曜と日曜の SMS が無料になる。
Text & Web パッケージを選択し、
適宜 Web Pack を追加購入することにより、
Web 料金を安く抑えることができるが、
例えば 30日間に 1GB 使う場合は、
£20 (£10 の Top up と Web Pack 2個) かかってしまうし、
何より Web Pack を忘れずに追加購入するのが面倒くさい。
短期滞在で 500MB 以内で済むのであればよいが、
1週間を超える滞在で、
500MB 以上使う場合は、
Vodafone は不適当な SIM だと思う。
3UK (Three)
ロンドンに到着した翌日 (二日目)、
都心を散歩していると
3 Store があったので、
£1 の SIMカードと、
£15 Top up Voucher を購入した (合計£16)。
Three は、
香港でも愛用しているキャリアなので期待大。
お店の人が忙しかったらしく、
SIMカードと Voucher を私に渡すと他の客の接客に行ってしまったので、
Top up および
「All-in-One 15 Add-on」
の購入を自分でやる羽目になった。
SIMカードをスマホに入れた後、
444 へダイヤルして Voucher の PIN を入力して Top up し、
Top up した£15 で Add-on を購入する。
残度数は£0 になってしまうが、
その日から 30日間、
300分までの通話と 3000通までの SMS と無制限の Web
(All-you-can-eat data) が利用できる。
なお、
My3 に登録しておくことにより、
Top up や Add-on をクレジットカード払いで購入することもできる。
他のケータイへの通話 (07 から始まる番号) や、
国内通話 (02 から始まる番号など) は、
300分までなら可能だが、
それ以外の通話 (087 から始まる番号など) は、
残度数が£0 だと発呼できない。
なお、
英国の電話番号体系は、
日本の電話番号体系と似ていて、
国内通話は最初に 0 が付き、
国外からかける場合は、
最初の 0 を除いた番号に英国の国際プレフィックス +44 を付ける。
Add-on を購入しない場合、
通話料は 26ペンス/分、
Web の料金は Top up ごと 150MB までは無料で、
それを超えると 11ペンス/MB もする。
150MB 以上は決して使わないというのでもない限り Add-on は必須だろう。
1週間〜1ヶ月の滞在で、
スマホで Web を使いまくる場合は、
3UK は適した SIM だと思う。
あえて欠点をあげるとすれば、
2G で使えないことくらい?
大きな建物の中など、
2G (EDGE) の電波は届くが 3G だと電波が弱すぎる場合があり、
不便に感じたケースがあった。
また、
後述する giffgaff の月£10 と比べると割高。
T-Mobile
ロンドン滞在二日目、
ホテルに帰ると
T-Mobile,
Orange,
Lebara
の SIM が部屋に届いていた。
前述したように Vodafone SIM はスマホで使うには不適当
(Web 料金が高くつく) なので、
Vodafone SIM の残度数が£0 になり次第、
別の SIM に乗り換えることにする。
Lebara は国際電話が 1ペニー/分でかけられる
(インドなど)
ことを売りにしている
Vodafone の MVNO で、
Web 料金は 15ペンス/MB と、
とんでもなく高額 (100MB 使うと£15 になってしまうし、Vodafone の Web Pack や 3UK の Add-on のような割引もない) なので、
候補から外す (← なら free SIM を申し込むな、と言われそう ^^;)。
T-Mobile と Orange は 2009年に合併している。
ブランド名こそ異なるが、
通信網は統合しているし、
料金体系もよく似ている。
どちらかを使ってみれば充分だろう、
というわけで T-Mobile を使ってみることにした。
T-Mobile の通話料は 30ペンス/分、
Web 料金は 1日最大£1。
£5 を Top up すると、
一ヶ月間有効な
「free internet」
をサービスすると説明書等に書かれているが、
£5 を Top up しても、
相変わらず毎日£1 づつ残度数が減り続けた。
仕方ないので
「30 day Internet Booster」
を購入することにする。
「MONTHWEB」
という文字列を、
441 へ SMS で送れば、
残度数から£5 が差し引かれ、
30日間無料で Web が使えるようになる。
これで安心...
ところが!
わずか 5日後、
以下のような SMS が届いた:
Just to let you know you have now reached 80% of your monthly Fair Use Policy.
Visit t-mobile.co.uk/broadbandhelp for info on what to expect
if you reach 100%.
2011年1月10日から、
1ヶ月あたりのデータ量が 500MB に制限されたらしい。
500MB に達しても、
通信できなくなるわけではないようだが、
なんらかの帯域制限がかかるのだろう。
1ヶ月で 500MB というのは、
いかにも少ない。
また、
T-Mobile には
Google Talk が使えないという
(私にとっては) 致命的な問題がある。
Google Talk アプリを起動しても、
ログインできないと表示される。
おそらく Google Talk が必要とするポートがブロックされているのだろう。
というわけで使用を断念した。
スマホで使う場合、
T-Mobile は論外な SIM だと思う。
O2
ロンドン滞在三日目、
O2, Vodafone の SIM が届いた。
ところが、
四日目以降は届かなくなった
(後にホテル側の不手際と判明)。
まだ届いていない SIM があるのに...
特に、
本命の giffgaff が届いていないのが痛い。
前述したように Vodafone はスマホで使うには不適当、
T-Mobile は論外なので、
O2 を使ってみることにした (滞在七日目)。
O2 の通話料は 25ペンス/分、
Web 料金は 1日最大£1。
私が申し込んだ
free SIM は
Text & Web プランなので、
£10 以上 Top up すると、
300 text と 500MB web が無料になる。
プラン (tariff) は他に、
Unlimited,
simplicity,
International などがある。
SIM を申し込むときにプランを指定できる他、
Unlimited と Text & Web プランは、
21300 宛に SMS を送ることにより変更できる。
その他のプランは 2202 に電話をかけて変更する。
| 21300 宛 SMS | プラン | Top up で得られる無料特典 |
|---|
| NOLIMIT | Unlimited |
£10-14: O2 同士の text が無制限
£15: O2 同士の通話 & text が無制限 |
| - | simplicity |
£7.50: 無制限 text |
| OFFER | Text & Web |
£10-14: 300 text, 500MB web
£15-29: 500 text, 500MB web
£30+: 無制限 text, 500MB web |
| - | International |
£10-14: O2 同士の text が無制限
£15: O2 同士の通話 & text が無制限 |
SIM をスマホに入れると、
何もしなくても (まだ Top up していないのに)
着信できた。
もちろん発信はできない。
My O2 に登録し、
£10 を Top up すると (現地時刻 22:01)、
発信およびインターネットへアクセスができるようになった。
ところが、
My O2
で残度数確認をしようとしてもエラーが表示される。
仕方ないので
My O2 アプリをインストールしてみたら、
残高 (balance) とプラン (tariff) が表示された。
しかし、
表示された残高は£9。
まだ通話をしていないので Web 料金が差し引かれたものと思われるが、
500MB web が無料になるのではなかったのか?
tariff には、ちゃんと
「Free UK texts to standard UK mobiles and 500MB Internet in UK.」
と表示されているのに...?
日付が変わるとさらに£1 引かれて残高が£8 になってしまった。
My O2 でエラーが表示されることから考えて、
SIM の activate が完全には完了していないのだろう。
いったいどーいうこと? と思っていたら、翌朝 9:01 に、
O2: Now you're up and running, go to o2.co.uk/hello to check all your Pay & Go benefits and the many ways you can top-up. To stop texts, call 2220.
という SMS が届いた。
夜間 22:00 〜 9:00 は、SIM の activate 処理 (の一部) が止まってたっぽい。
22:00 以降に activate すると、
処理が翌日まわしになるということのようだ。
続いて、9:14 に
O2: You've now got 300 free UK text and 500MB internet to use this month.
Remember to top up at least £10 by 13 Jul
to get your free allowance next month.
という SMS が届き、
無事 300 text と 500MB web が無料になった。
人手で activate 処理をやってるんじゃあるまいし、
夜間は手続きが止まるというのはいかがなものかと思う。
短期滞在で、
500MB 以内で済む場合は、
O2 は悪くない SIM だと思う。
500MB を超えると、
毎日£1 かかってしまうので、
滞在日数が長くなると割高。
Vodafone と比べると、
3G のサービスエリアが狭いように感じた。
大きな建物の中や郊外など、
すぐ 2G に切り替わってしまう印象がある。
giffgaff
giffgaff の SIM は、
他のキャリアと異なり街中で買うことができない。
Web で free SIM を申し込んで郵送 (英国内の住所のみ)
してもらう必要がある。
ホテル側の不手際で、
私宛の郵便物が一週間ほどホテル内に留め置かれてしまったため、
giffgaff SIM を入手できたのはロンドン滞在八日目の晩だった。
もちろん、
何度かホテルのフロントに郵便物が届いていないか問合わせていたのだが、
その時の担当者が宿泊者宛の郵便物がホテルでどう扱われるか、
分かっていなかったようだ
(オリンピック準備の一環で新人のトレーニングを兼ねて、
フロントを新人に担当させていた模様)。
なお、
giffgaff の他、
Vectone,
delight,
LycaMobile
の SIM も届いたが、
Vectone と delight は (論外な) T-Mobile の MVNO なので見送り
(Vectone は 1ヶ月 1GB まで許容していることを後で知った)、
LycaMobile は O2 の MVNO だが
2G のみらしいので見送った。
いずれも安い国際電話を売りにしているキャリアなので、
私のニーズには合わない。
giffgaff SIMカード表面に印字されている 6桁の code を、
SIM activation ページで入力し、
Top up か goodybag
(またはその両方) を購入すると
activate できる。
SIM をケータイに入れる必要はなく、
Web 上で完結するので、
英国外からでも activate できそう。
goodybag というのは 1ヶ月間有効な通話や通信のパッケージで、
250分の通話と無制限 text と無制限 web のパッケージが£10 で購入できる。
元々 giffgaff SIM ユーザ同士の通話は無料なので、
goodybag さえ購入しておけば、
残度数は£0 のままで済んでしまうのではないか?
私も
「£10 goodybag」
だけ購入し、
Top up は行なわなかった。
他のケータイへの通話 (07 から始まる番号) や、
国内通話 (02 から始まる番号など) は、
250分まで goodybag に含まれるが、
それ以外の通話 (国際電話や 087 から始まる番号など) は、
残度数が£0 だと発呼できない。
goodybag を利用しない場合の
通話料は 10ペンス/分、
Web 料金は 20MB まで 20ペンス/日だが、
20MB を超えると 20ペンス/MB も課金されるので危険。
スマホを使う場合、
goodybag が必須だろう。
activate が完了すると My giffgaff
で電話番号を確認することができる
(完了するまでは自分の電話番号さえ分からない)。
ところが、
クレジットカードでの支払い完了が 21:57 で、
22:00 までに activate がギリギリ間に合わなかったようで、
完了が翌日まわしになってしまった (通常は 30分以内に完了する)。
おそらく、
O2 側の手続きが 22:00 までに完了しなかったのだろう。
翌日 5:18 に、
ようやく手続きが完了し、
通信・通話ができるようになった。
giffgaff は O2 の MVNO なので、
通信・通話を利用した感じは O2 と変わらない。
ただし APN は O2 とは異なり、
以下のように設定する必要がある:
| APN | giffgaff.com |
|---|
| ユーザー名 | giffgaff |
|---|
| パスワード | password |
|---|
| MMSC | http://mmsc.mediamessaging.co.uk:8002 |
|---|
| MMSプロキシ | 193.113.200.195 |
|---|
| MMSポート | 8080 |
|---|
| APNタイプ | default,supl,mms |
|---|
1週間〜1ヶ月の滞在で、
スマホで Web を使いまくる場合は、
giffgaff は最適な SIM だと思う。
3UK と同様 Web が無制限で、
3UK より安い。
3UK と異なり 2G も使えるので、
3G の電波が届かないところでも使える。
あえて欠点をあげるとすれば、
O2 と同様、
3G のサービスエリアが Vodafone より狭いことくらい。
大きな建物の中や郊外など、
すぐ 2G に切り替わってしまう印象がある。
郵送以外の方法で SIM を入手できない点も残念。
ヒースロー空港の自販機で (£10 でもいいから) 入手できるだけでも、
ぜんぜん利用のしやすさは変わってくるのにと思う。
あるいは、
有料で構わないので英国外への発送もできるようにすれば、
出発前に日本で SIM を取り寄せることができるのにと思う。
 到着ロビーへ出て左側へ進んだところに、
中華電信,
台灣大哥大,
到着ロビーへ出て左側へ進んだところに、
中華電信,
台灣大哥大,


 Data Package が Monthly Plan 必須になってしまうと、
基本料金無料をウリにしていた (スマホな) GoPhone の立場は、
どーなるんだ...
と思っていたら、
Data Package が Monthly Plan 必須になってしまうと、
基本料金無料をウリにしていた (スマホな) GoPhone の立場は、
どーなるんだ...
と思っていたら、 よほど在庫が積み上がってるのか、
ドコモ SC-04D Galaxy Nexus が新規一括 0円で売っていた。
あんなに
よほど在庫が積み上がってるのか、
ドコモ SC-04D Galaxy Nexus が新規一括 0円で売っていた。
あんなに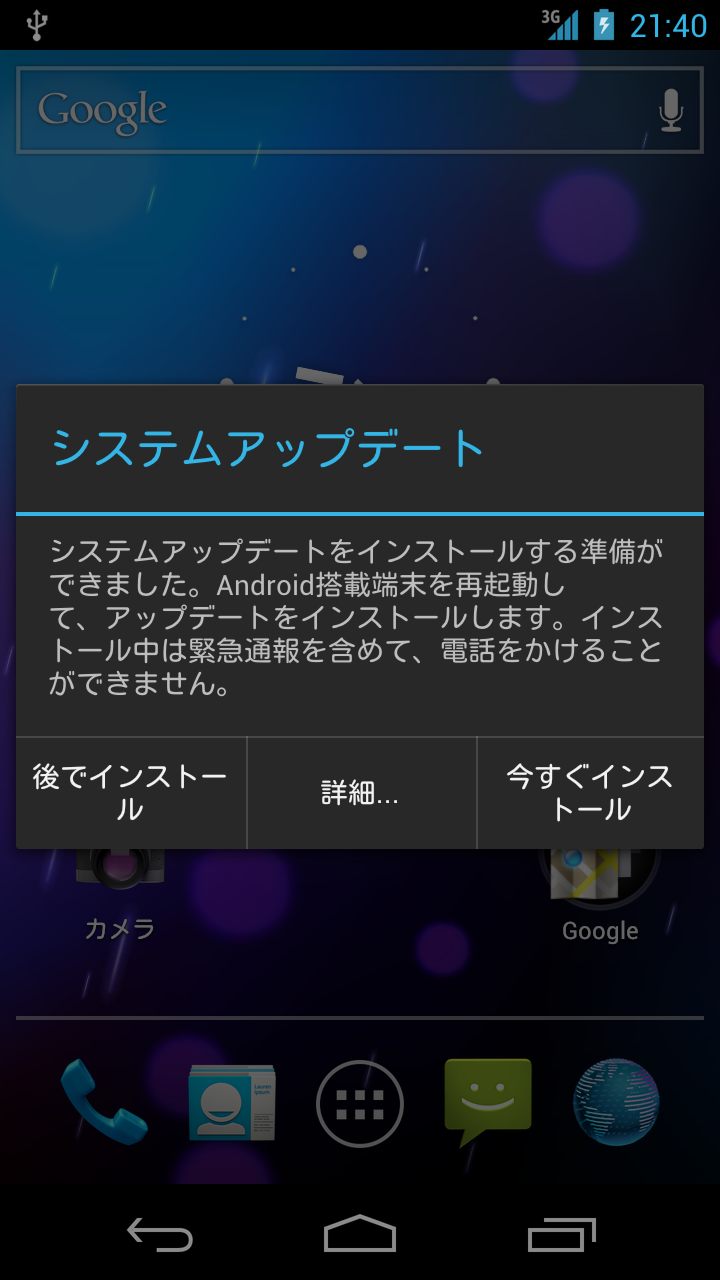

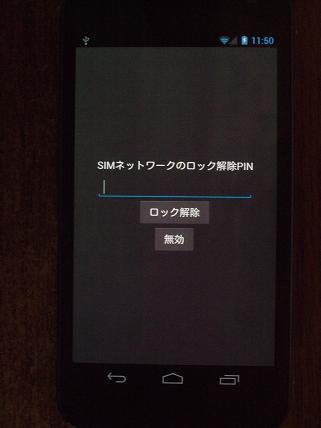 というわけで万策尽きたので、
解除コード (Unlock Code)
を業者から買うことにした。
だいたい $30 前後で、
ドコモ (3,150円) より若干安い。
この期に及んでドコモのサービスを使わないのは、
前述した懸念点があるのと、
ドコモショップでは
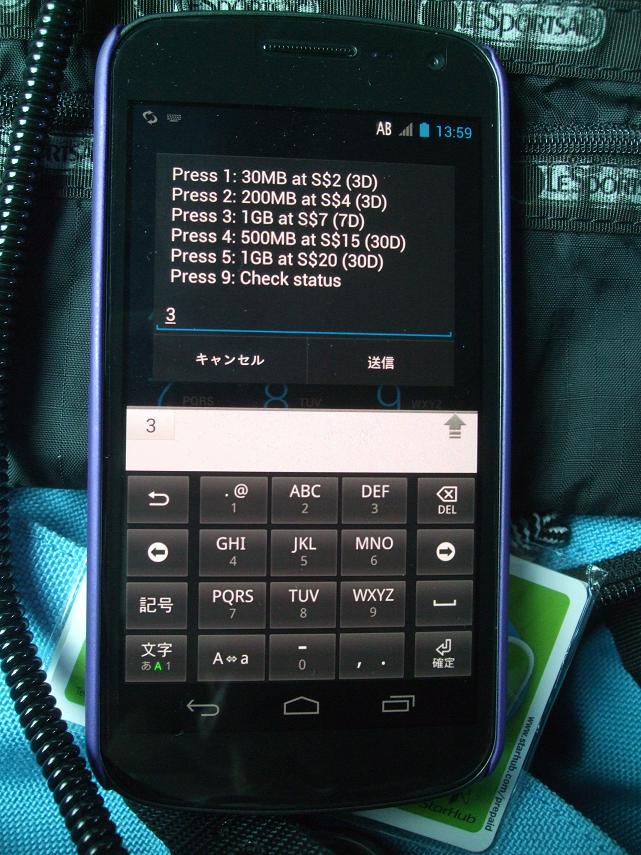
というわけで万策尽きたので、
解除コード (Unlock Code)
を業者から買うことにした。
だいたい $30 前後で、
ドコモ (3,150円) より若干安い。
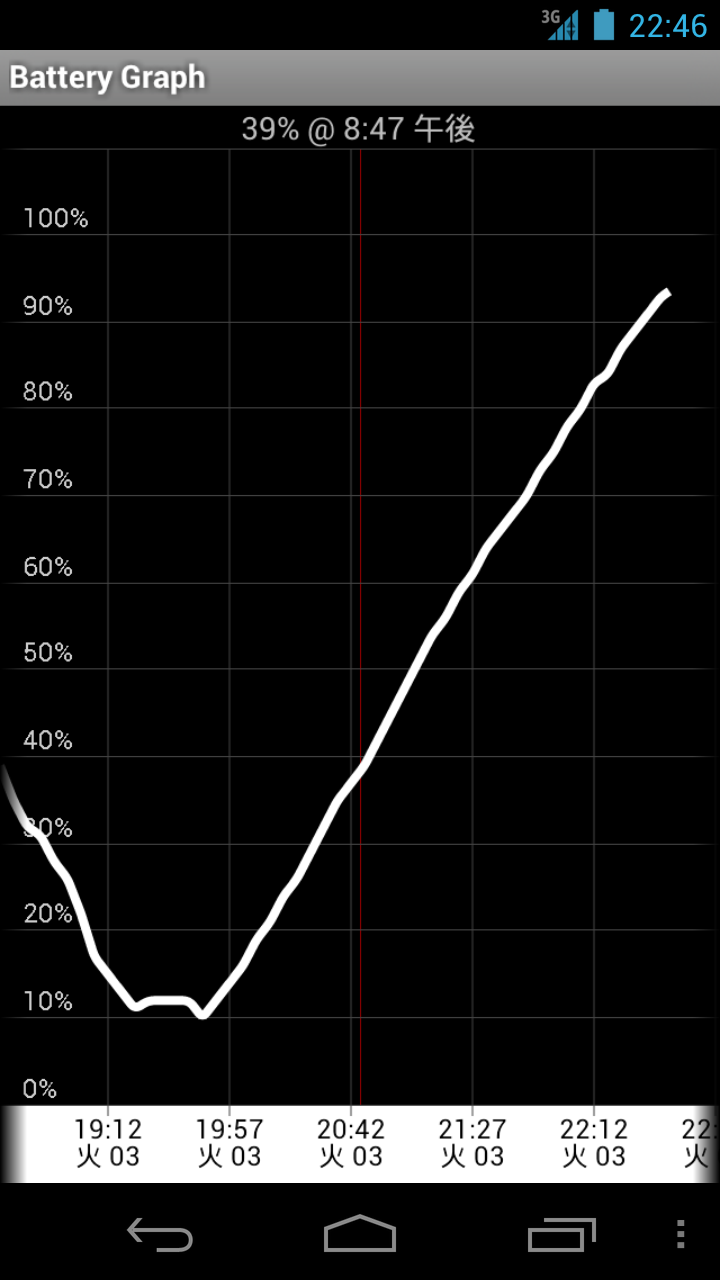
この期に及んでドコモのサービスを使わないのは、
前述した懸念点があるのと、
ドコモショップでは










{kind=link}